






科技頻道
北大楊仝團隊發(fā)布FairyR1模型:百分之五參數(shù)量數(shù)學和代碼能力超越滿血DeepSeek
北京大學楊仝教授團隊近期發(fā)布了其在高效大型語言模型研究方向的一項新成果——FairyR1-32B模型。該模型基于DeepSeek-R1-Distill-Qwen-32B基座,通過結(jié)合微調(diào)與模型合并技術(shù)構(gòu)建。研究探索了在參數(shù)量大幅減少的情況下,模型在特定任務上實現(xiàn)與更大模型相當甚至更優(yōu)性能的可能性。該研究得到了國家自然科學基金委項目(624B2005, 62372009)的資助。FairyR1-32B模型已在huggingface開源:https://huggingface.co/PKU-DS-LAB/FairyR1-32B。
FairyR1-32B模型是在團隊前期TinyR1工作基礎(chǔ)上進行的進一步探索,沿用了“分合蒸餾”的研究思路,提出了多種改進方法,包括自我合并、多教師交叉蒸餾、輕蒸餾等方法,并在數(shù)據(jù)處理進行了優(yōu)化,模型精度有了顯著提升。
本次工作重點改進了蒸餾數(shù)據(jù)的構(gòu)建流程,對來源于AI-MO/NuminaMath-1.5(數(shù)學)和open-thoughts/OpenThoughts-114k(代碼)等數(shù)據(jù)集的原始數(shù)據(jù),通過多個“教師模型”生成答案,隨后對問答數(shù)據(jù)進行精心篩選、結(jié)構(gòu)調(diào)整與思維鏈優(yōu)化,并進行多階段篩選。篩選過程包括基于答案的正確性驗證(針對數(shù)學數(shù)據(jù)),以及基于長度的篩選(數(shù)學數(shù)據(jù)保留2k-8k tokens范圍,代碼數(shù)據(jù)保留4k-8k tokens范圍),最終構(gòu)建了更具針對性的約6.6k條數(shù)學數(shù)據(jù)和約3.8k條代碼數(shù)據(jù)用于訓練。
在模型結(jié)構(gòu)方面,研究團隊嘗試訓練兩個領(lǐng)域(數(shù)學和代碼)的專業(yè)模型進行合并,旨在進一步優(yōu)化流程和資源消耗。這兩個專業(yè)模型在一致的訓練參數(shù)下(例如相同的學習率和批次大小)獨立訓練約5個周期后,利用AcreeFusion工具進行了合并。在多個公開基準測試中,F(xiàn)airyR1展現(xiàn)出了在低參數(shù)量下的競爭力表現(xiàn)。以下為FairyR1與DeepSeek-R1-671B及DeepSeek-R1-Distill-Qwen-32B在部分基準上的得分對比:
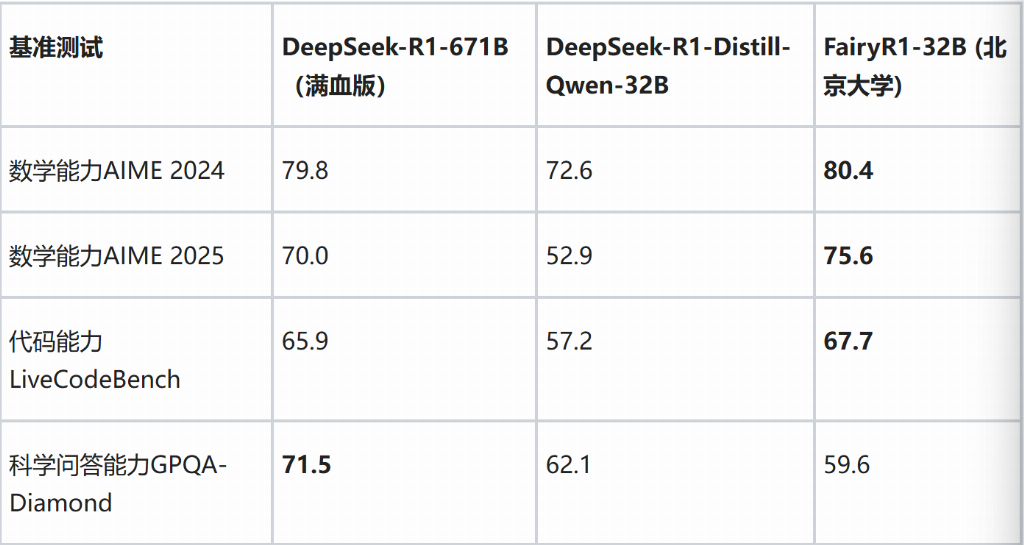
從測試結(jié)果可以看出,F(xiàn)airyR1-32B在AIME 2025和LiveCodeBench基準上得分略高于DeepSeek-R1-671B,在AIME 2024上表現(xiàn)接近。在GPQA-Diamond科學基準上,F(xiàn)airyR1的得分低于DeepSeek-R1-671B。這些結(jié)果表明,F(xiàn)airyR1在采用DeepSeek-R1-Distill-Qwen-32B基座并經(jīng)過特定技術(shù)處理后,能夠在約5%參數(shù)量的情況下,在數(shù)理和編程等領(lǐng)域?qū)崿F(xiàn)與大型模型相當或略優(yōu)的性能水平,但在科學等其他領(lǐng)域可能存在差距。這項工作探索了通過優(yōu)化的數(shù)據(jù)處理和模型融合技術(shù),在保證特定任務性能的前提下,大幅降低模型規(guī)模和潛在推理成本的可能性。
北京大學楊仝教授團隊表示:“FairyR1-32B模型是我們探索高效大型語言模型技術(shù)路線的階段性成果。通過對蒸餾和合并方法的改進,我們初步驗證了在有限資源下實現(xiàn)高性能模型的可行性。”
團隊成員:李旺、周俊廷、劉文睿、姚一倫、王融樂、楊仝

本文僅供讀者參考,任何人不得將本文用于非法用途,由此產(chǎn)生的法律后果由使用者自負。如因文章侵權(quán)、圖片版權(quán)和其它問題請郵件聯(lián)系,我們會及時處理:tousu_ts@sina.com。


打開微信,點擊底部的“發(fā)現(xiàn)”
使用“"掃—掃"即可將網(wǎng)頁分享至好友











舉報郵箱: Jubao@dzmg.cn 投稿郵箱:Tougao@dzmg.cn
未經(jīng)授權(quán)禁止建立鏡像,違者將依去追究法律責任
大眾商報(大眾商業(yè)報告)并非新聞媒體,不提供任何新聞采編等相關(guān)服務
Copyright ©2012-2023 dzmg.cn.All Rights Reserved
湘ICP備2023001087號-2